RAG系统中的文档分块策略
检索增强生成(RAG)已成为人工智能领域的关键技术,通过结合外部知识库来提升大型语言模型的输出质量。而在RAG系统中,文档分块策略是一个看似简单却至关重要的环节,它直接影响检索准确性和系统整体效率。本文将探讨各种分块策略的工作原理、优缺点及适用场景,帮助你为特定应用场景选择最佳方案。
约一千五百字·读约五分钟 · English

检索增强生成(RAG)已成为人工智能领域的关键技术,通过结合外部知识库来提升大型语言模型的输出质量。而在RAG系统中,文档分块策略是一个看似简单却至关重要的环节,它直接影响检索准确性和系统整体效率。本文将探讨各种分块策略的工作原理、优缺点及适用场景,帮助你为特定应用场景选择最佳方案。
为什么分块如此重要?
即使当前LLM的上下文窗口不断扩大,高效的分块策略仍然不可或缺,主要原因包括:
- 克服Token限制:将文本分割成符合模型处理能力的片段
- 提升检索精度:更容易定位与查询高度相关的信息
- 降低计算成本:减少处理不必要大量上下文的开销
- 提高信噪比:过滤无关内容,提供更精炼的信息
核心分块策略详解
1. 固定大小分块
 工作原理:基于预设的字符数、单词数或token数量将文本切分为统一大小的片段。
工作原理:基于预设的字符数、单词数或token数量将文本切分为统一大小的片段。
优势:
- 实现简单直接
- 尺寸统一可控
- 通用性强,无特殊依赖
劣势:
- 可能在句子或段落中间断开
- 不考虑文档结构和语义
适用场景:内容结构统一的文档、标准化数据集、用户生成内容
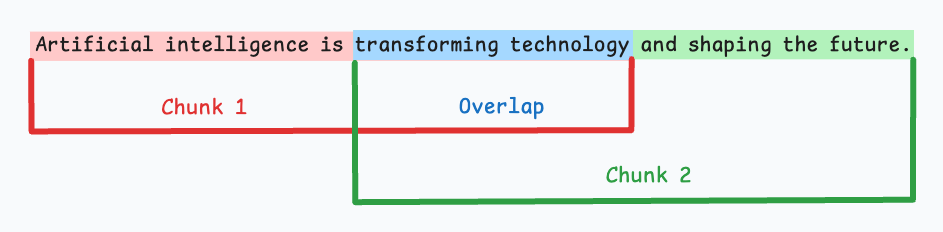
2. 重叠分块技术
工作原理:在连续文本块之间共享一定比例的内容(通常为块大小的10-20%)。
优势:
- 减少边界信息丢失
- 提升上下文连续性
- 改善检索准确性
劣势:
- 数据冗余
- 增加存储和计算负担
适用场景:与固定大小分块结合使用,特别适用于发言人频繁变化的对话记录
3. 递归分块
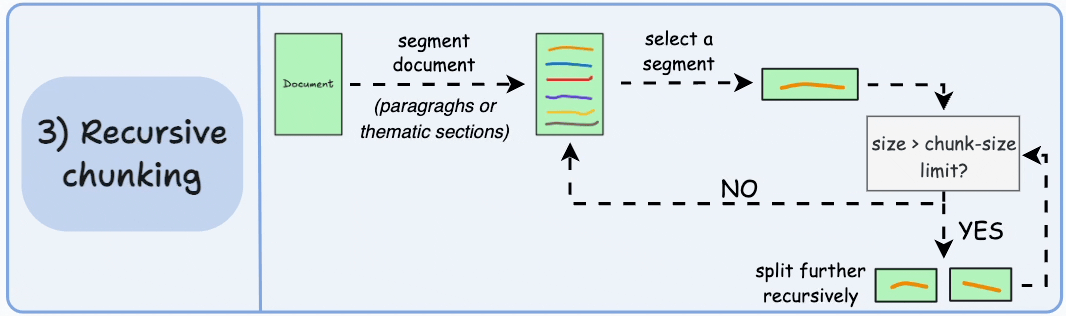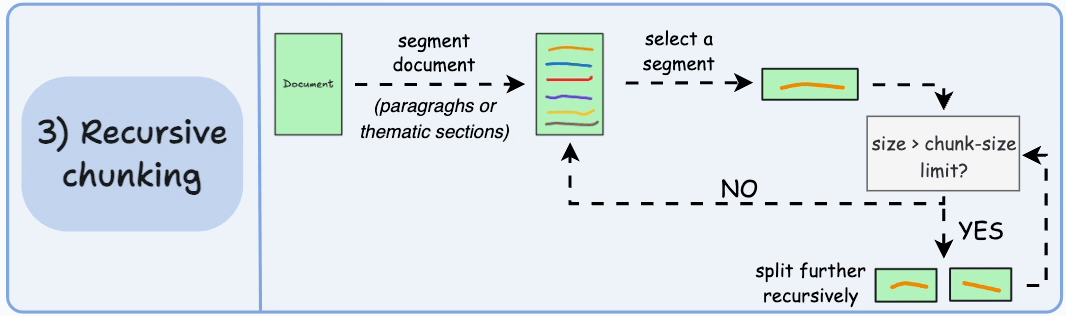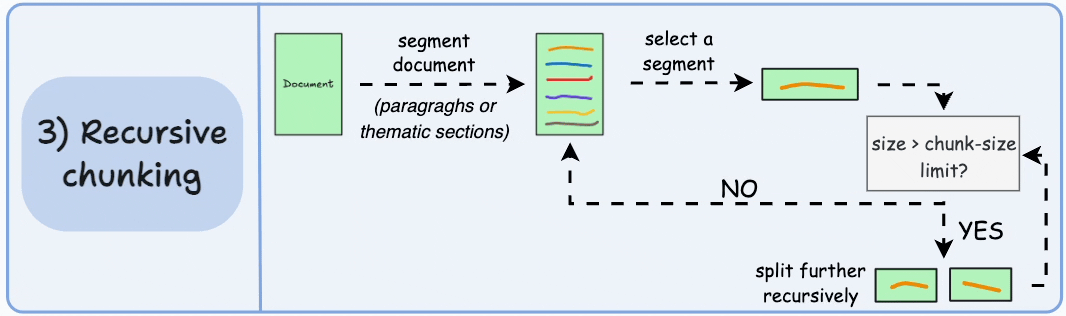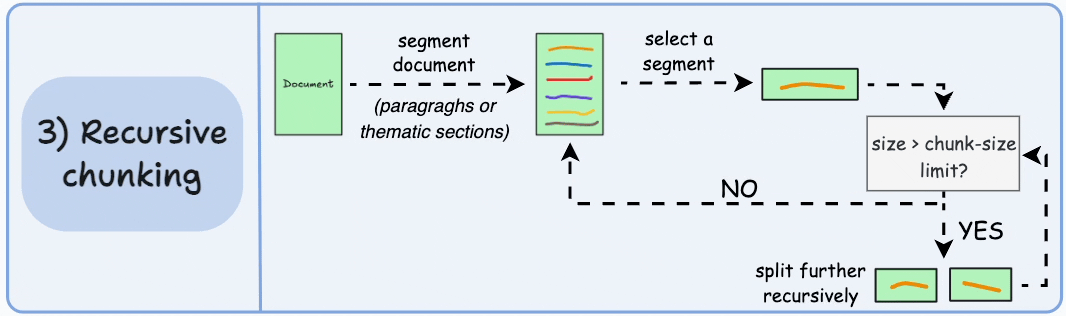 **工作原理**:使用层级化分隔符(如段落符\n\n、句子符\n、空格)递归切分文本。
**工作原理**:使用层级化分隔符(如段落符\n\n、句子符\n、空格)递归切分文本。
优势:
- 更好地保持文本结构与语义
- 适应性强,兼顾多种数据类型
- 减少文本碎片化
劣势:
- 处理速度可能较慢
- 无法保证块大小严格一致
- 计算复杂度较高
适用场景:纯文本文档、层级化文本、需要保持文档结构的场合
4. 文档特定分块
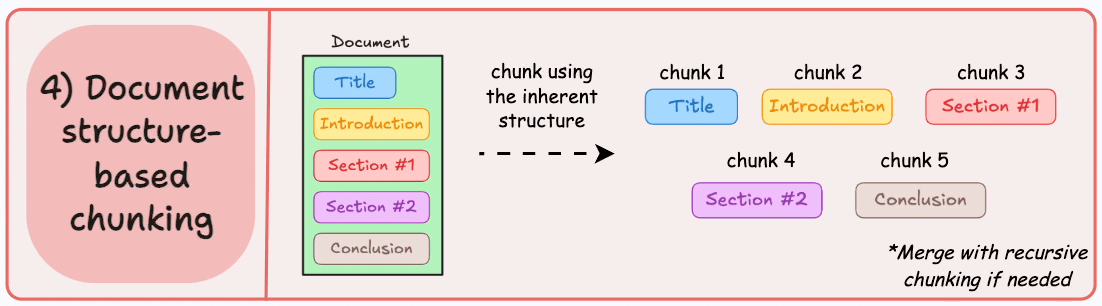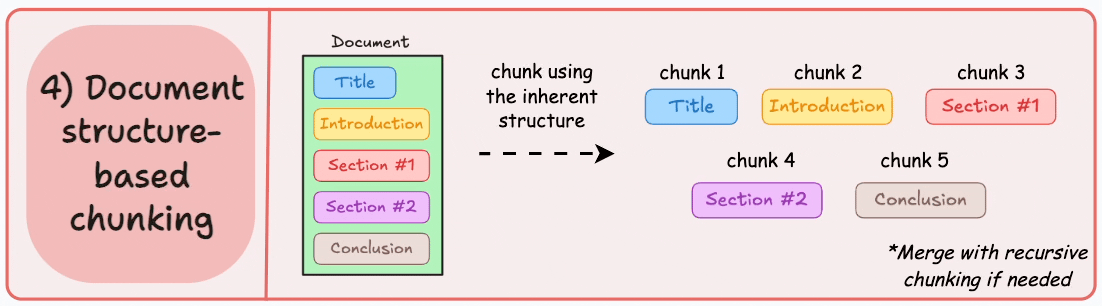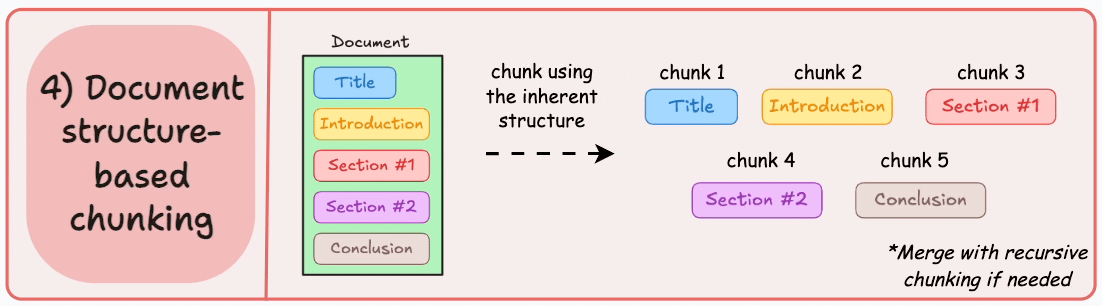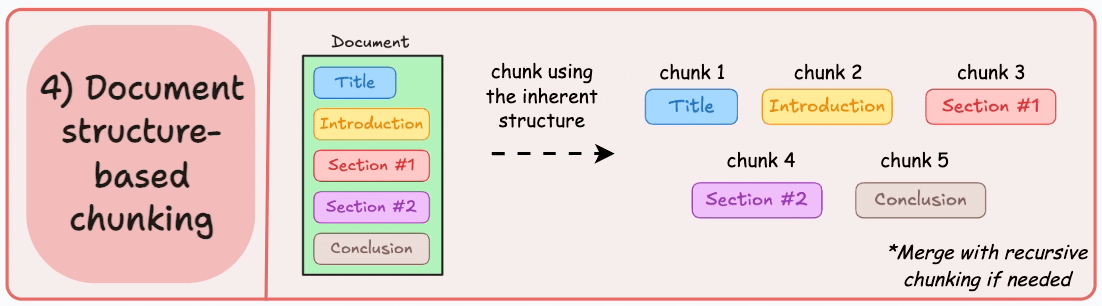
工作原理:利用文档固有的逻辑结构(标题、段落、章节等)进行分块。
优势:
- 保持作者意图和逻辑流程
- 高上下文相关性
- 更好地保持语义完整性
劣势:
- 高度依赖文档结构清晰度
- 实现复杂,需针对不同格式开发特定解析器
- 对非结构化文本效果有限
适用场景:技术手册、研究论文、法律文件、代码文档
5. 语义分块
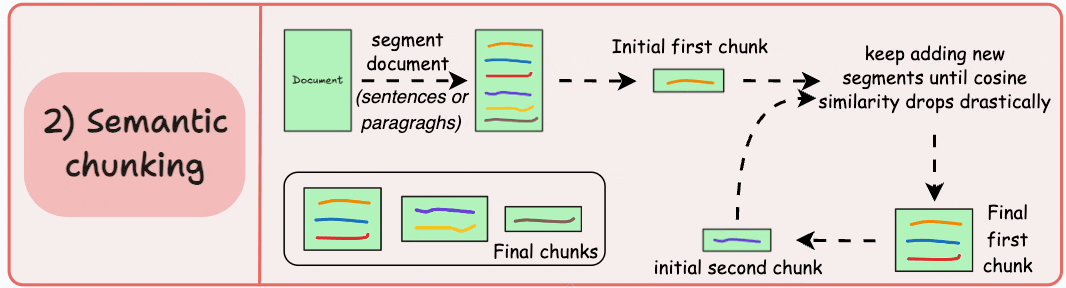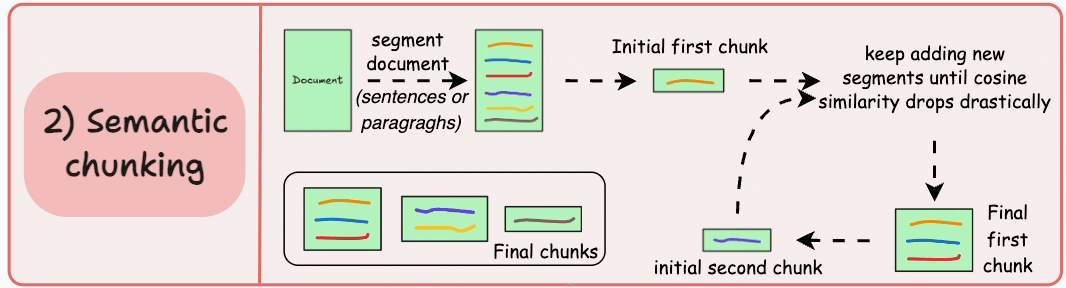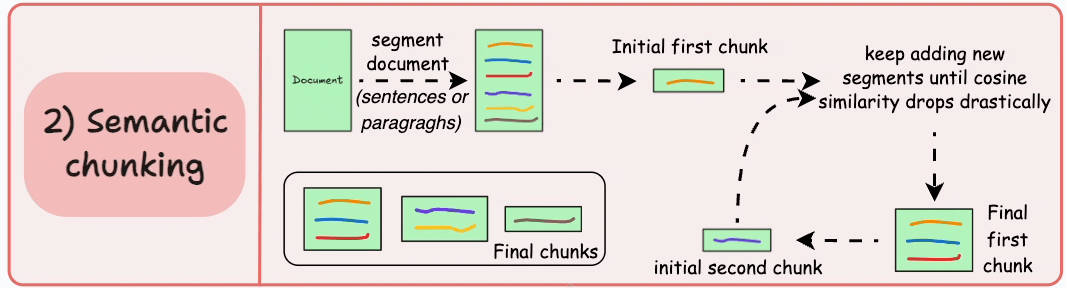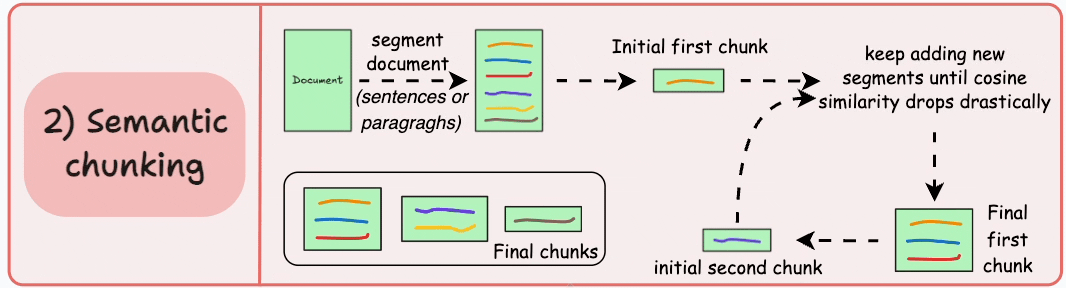 **工作原理**:基于句子或文本片段的语义相似性,识别主题转变点进行分组。
**工作原理**:基于句子或文本片段的语义相似性,识别主题转变点进行分组。
优势:
- 检索质量高
- 每个块代表完整概念
- 避免将多种意义嵌入单一向量
劣势:
- 计算成本高
- 需要嵌入模型和相似性计算
- 参数调整复杂
适用场景:法律文件分析、医学研究、需要高度上下文准确性的任务
6. 混合分块
工作原理:结合多种分块技术,发挥各自优势并弥补不足。
优势:
- 适应性强,可定制
- 改善上下文语境化
- 潜在更高准确性
劣势:
- 设计和实施复杂
- 计算成本高
- 优化困难
适用场景:复杂异构文档、对准确性要求极高的应用场景
如何选择最适合的分块策略?
选择合适的分块策略需要考虑多个因素:
-
文档类型与结构
- 结构化内容适合文档特定分块
- 非结构化内容适合递归分块或语义分块
-
查询类型与任务
- 特定事实查询需要细粒度分块
- 主题性查询适合与文档章节对齐的块
-
LLM Token限制与资源约束
- 确保块大小符合模型处理能力
- 权衡计算资源与分块复杂度
-
上下文保持与粒度平衡
- 小块提供精确度但可能失去上下文
- 大块保持上下文但可能超出限制
实用建议
- 从简单开始:先尝试带有重叠的递归分块建立基线
- 深入理解数据:分析文档类型、结构和内容模态
- 持续评估优化:测试不同参数组合,监控性能指标
- 不忽视重叠:特别是对固定大小分块,重叠参数调整至关重要
- 平衡成本效益:高级策略可能带来性能提升,但计算开销也更大
未来展望
RAG仍在快速发展,值得关注的趋势包括:
- 智能体分块:利用LLM决定文档切分方式
- 上下文增强分块:将前面块的摘要添加到当前块中
- 多模态分块:处理文本与其他模态数据关系
- 基于图的分块:使用图数据库存储块之间的关系
结语
文档分块看似简单,实则兼具各方面权衡,需要深入理解、精心设计和反复实验。随着RAG系统的普及,高效的分块策略将持续发挥关键作用,帮助模型生成更高质量、基于事实且与用户需求高度相关的响应。
没有放之四海而皆准的最优分块方案,重要的是根据特定场景选择和选择合适的策略,在上下文完整性、检索精确度和计算效率之间找到理想平衡点。
Mttao GitHub ↗
探索技术与生活的智慧